Jun
7
Recommending Links for articles in Wikipedia
Filed Under sayansi, teknolojia by Mucheru
In senior year of college, I took an class that blended information theory, algorithms and networking. It was called “Algorithms at the end of the wire”. My project for that class was an application that finds links for articles in Wikipedia.
Working off the ideas presented in class on search results ranking and vector space models, we proposed that given a query article (an article to add links in), we can find some k articles already in Wikipedia that are most similar to it. We can then we can use the links in those articles to infer the links to create in the query article. In particular, each of the neighboring articles could suggest links for text that they had in common with the query and the set of neighbors would vote on the link with weighing applied based on how close the particular voting article was to the query article. As the mechanism for determining the k nearest neighbors, we would fetch articles from the Wikipedia corpus that had text occurring in the query article then rank the results and pick the top k. Ranking was done separately using PageRank and using Latent Semantic Indexing then the rankings were aggregated.
You can download a prototype of an editor implementing our algorithm here . The editor depends on a web service so you need to be connected to the internet to use it. This is a C# application so you can run it in windows or in Linux using Mono.
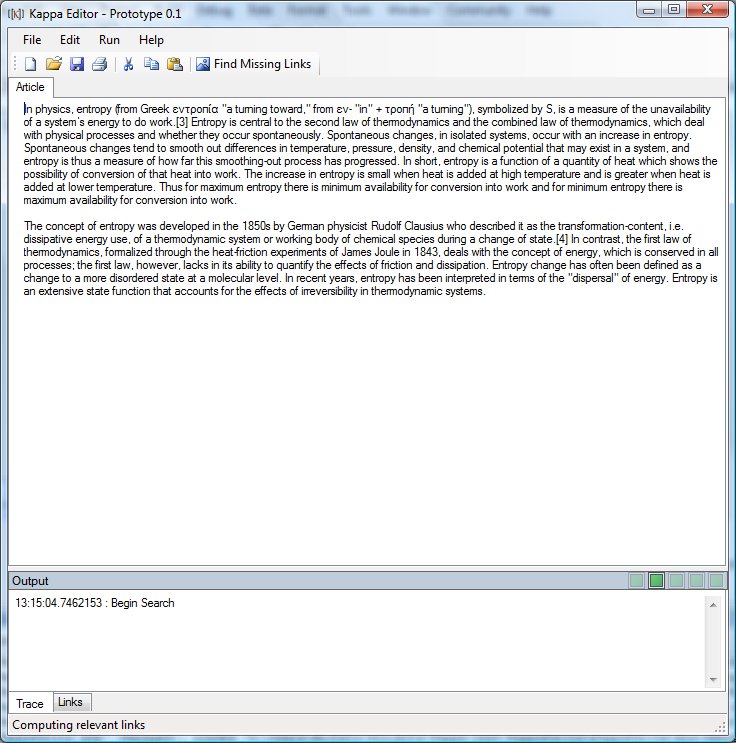
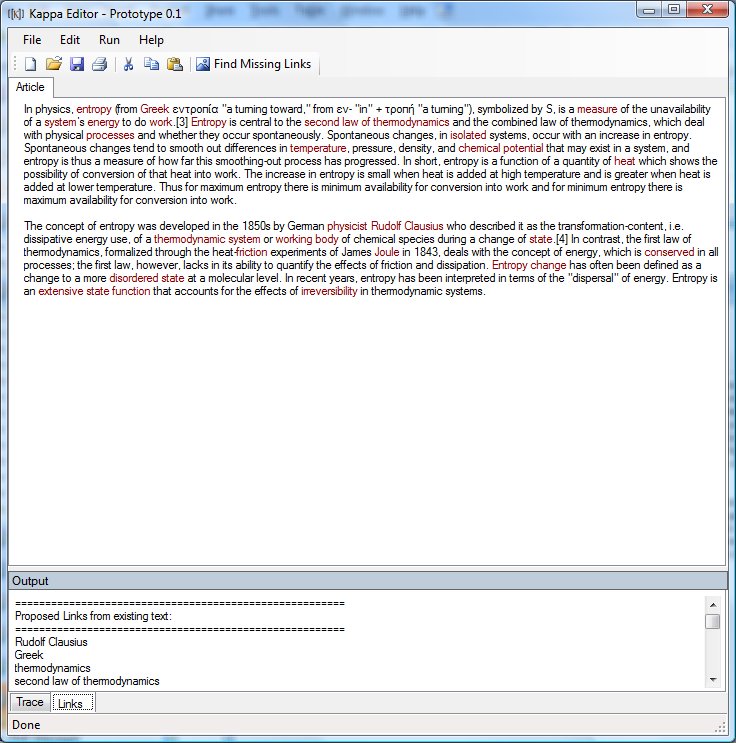
I’ve had lots of fun with this project – it’s a problem that poses lots of interesting questions on the design and implementation fronts some with nice theoretical dimensions. The problem of figuring out what a section of text is about it non-trivial. It’s a whole field of research. I found myself reading many papers on optimized matrix operations for sparse matrices. I’m still trying to solve the problem of how to store the data on similarity of articles so as to speed up lookup for article we’ve seen before. There is a lot of literature on rank aggregation, k-nearest neighbor searches, text summarization etc.
The data involved is also fairly large – I used the English Wikipedia which was 15 GB at the time. I got tripped up a couple of times by data corruption when indexing or updating the collection. Failure recovery here was more important than in any of the projects I had worked on before this – if there was a fatal failure midway through indexing the collection, you wanted to avoid starting over from scratch. This called for better diagnostics and logging to figure out where the error occurred. Another framework problem to solve was how to pass information around. Initially, I had the full 15gb Wikipedia corpus on my machine and the editing application and project library could access the data directly. In my target deployment, the individual editors who would use this tool would not have to download the full dump. It was necessary to figure out a way of passing the editor just the information it requires. I ended up going with a SOAP web service and serializing objects to get them back and forth between client and server. A pdf poster with the design is found here.